
Funktionsweise der neuronalen Netzwerke
Im Herzen der Künstlichen Intelligenz (KI) schlagen die Neuronale Netzwerke - komplexe Gebilde aus Algorithmen, die es Maschinen ermöglichen, zu lernen, zu verstehen und Entscheidungen zu treffen. Diese faszinierenden Konstruktionen werfen Licht auf die Funktionsweise einer KI und zeigen, wie sie unsere Welt beeinflussen kann.
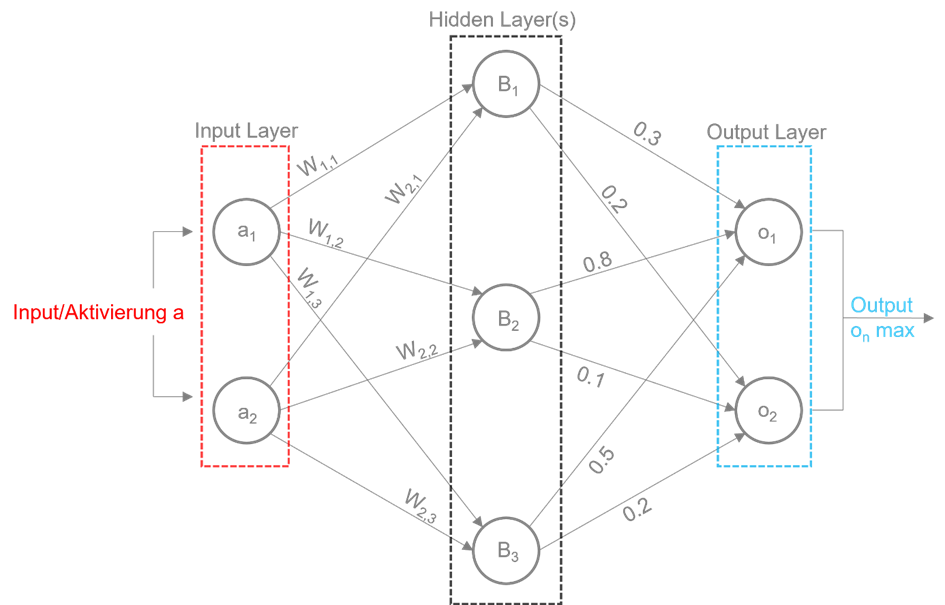
Neuronale Netzwerke sind computergestützte Modelle, die von der Funktionsweise des menschlichen Gehirns inspiriert sind. Sie bestehen aus vielen miteinander verbundenen Knotenpunkten, auch Neuronen oder Nodes genannt.
Jeder Knotenpunkt in einem neuronalen Netzwerk hat eine numerische Aktivierung, die meistens zwischen 0 und 1 liegt. Die Eingangsknoten oder Input Layer Nodes erhalten externe Aktivierungen, die als Eingabedaten dienen. Diese Aktivierungswerte werden dann mit den Gewichtungen (w) der jeweiligen Verbindungen zu den Neuronen der nächsten Ebene verrechnet. Somit werden die Werte an meist mehrere Hidden Layer weitergegeben.
In der Hidden Layer besitzt jeder Knotenpunkt einen sogenannten Bias (B), der dazu dient, die Aktivierung des Knotenpunkts zu beeinflussen. Die Aktivierung eines Knotenpunkts in der Hidden Layer wird wieder durch die Summe der gewichteten Eingänge (Aktivierungen der vorherigen Schicht multipliziert mit den Gewichtungen) und dem Bias berechnet. Diese berechnete Aktivierung wird dann durch eine Aktivierungsfunktion transformiert.
Die Aktivierungsfunktion entscheidet über Schwellenwerte, ob ein Neuron aktiv oder inaktiv geschaltet wird. Typische Aktivierungsfunktionen sind die Sigmoidfunktion, die Hyperbolic Tangent (Tanh)-Funktion oder die ReLU (Rectified Linear Unit)-Funktion.
Die aktiven Knotenpunkte in einer Schicht übermitteln dann ihre Aktivierungen an die Knotenpunkte in der nächsten Schicht. Dieser Prozess der Informationsübertragung und Berechnung wiederholt sich Schicht für Schicht, bis die Ausgabeschicht erreicht wird. Die Ausgabe mit dem höchsten Wert oder anders gesagt der höchsten Wahrscheinlichkeit wird dann als das Ergebnis des neuronalen Netzwerks zurückgegeben.
Funktionsweise ChatGPT
ChatGPT ist ein Sprachmodell, das auf der GPT (Generative Pre-trained Transformer)-Architektur basiert. Diese Architektur ermöglicht es dem Modell, Dialoge zu verstehen und entsprechend zu antworten.
Der Encoder ist der erste Teil des Modells. Er nimmt die Benutzereingabe entgegen und erstellt eine komprimierte Repräsentation dieser Informationen. Der Encoder analysiert den Text schrittweise und erstellt einen Zustandsvektor, der den gesamten Kontext enthält. Diese Zusammenfassung des Inputs wird als Kontextvektor bezeichnet.
Der Kontextvektor wird dann an den Decoder weitergegeben. Der Decoder ist für die Generierung der Antwort verantwortlich. Ähnlich wie der Encoder besteht der Decoder aus wiederholten Modulen. Er erhält den Kontextvektor und beginnt schrittweise die Antwort zu generieren.
Der Decoder arbeitet tokenweise und erzeugt die Antwort schrittweise, wobei er den aktuellen Zustand und den bisher generierten Text verwendet. Bei jedem Schritt wird ein Token generiert und zum generierten Text hinzugefügt. Dieser Prozess wiederholt sich, bis ein spezielles Token erreicht wird, das das Ende der Antwort markiert oder die maximale Länge der Antwort erreicht ist.

ChatGPT wurde durch zwei Arten trainiert: Unsupervised Learning (unüberwachtes Lernen) und Supervised Learning (überwachtes Lernen).
Im Unsupervised Learning werden große Mengen an Textdaten gesammelt, beispielsweise durch das Scrapen des Internets. Dieser Text wird verwendet, um den Encoder des Modells zu trainieren. Während dieses Prozesses lernt das Modell, die Struktur und Zusammenhänge in natürlicher Sprache zu erfassen. Das Training auf unüberwachten Daten kann mehrere Monate oder sogar Jahre in Anspruch nehmen, um ein tiefes Verständnis der Sprache zu entwickeln.
Nachdem der Encoder ausreichend trainiert wurde, erfolgt das Supervised Learning. Hier werden menschlich erstellte Dialogdatensätze verwendet, die aus Benutzereingaben und den entsprechenden Antworten bestehen. Diese Daten werden von menschlichen Aufsichtspersonen erstellt und verifiziert. Das Modell wird darauf trainiert, die richtigen Antworten für verschiedene Benutzereingaben vorherzusagen.
